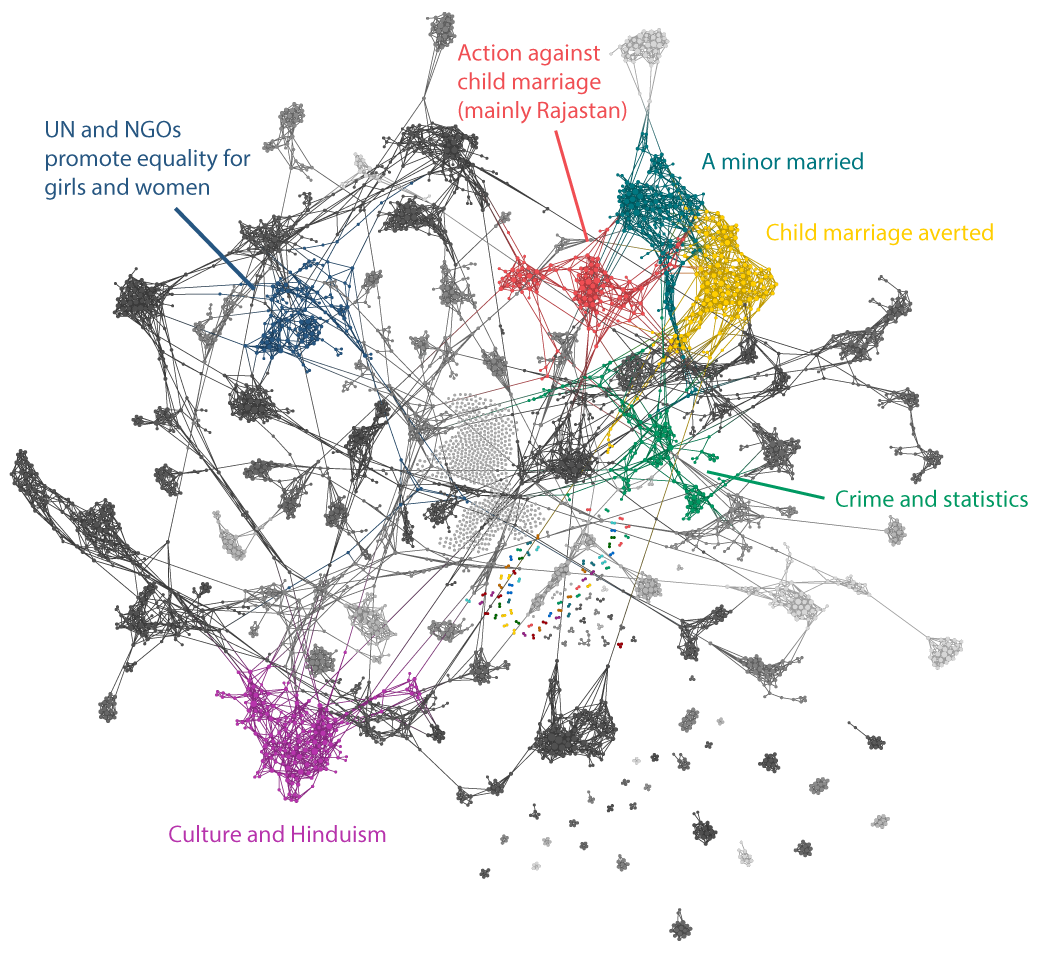
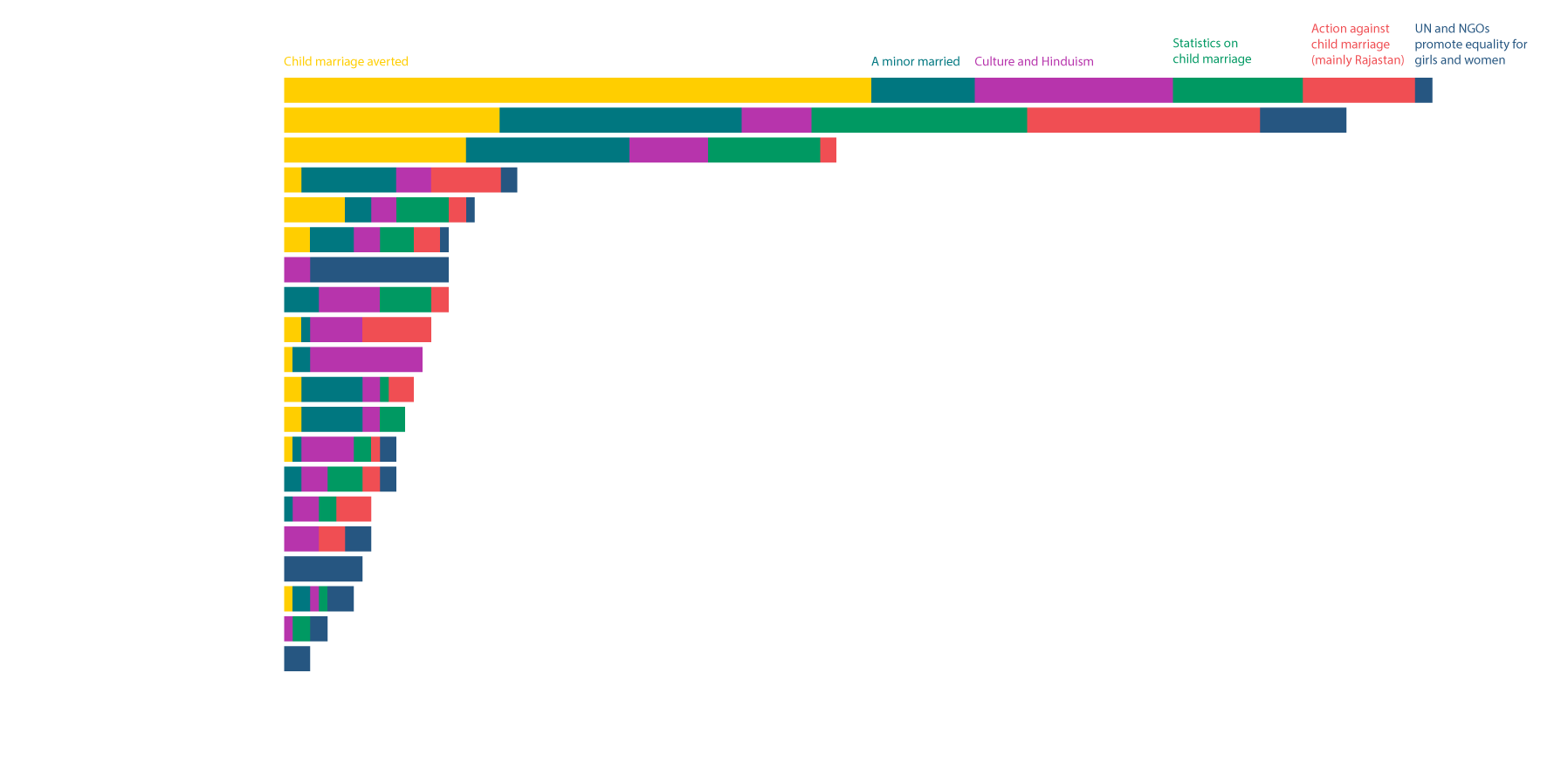
Google Trends
Search engines represent a common starting point for many people to gain information on a given topic. Google search offers the most comprehensive web portal to query this type of search trend data, which is why it has been used as the primary source of information for this study. Bing also offers a comparable service while Yahoo!, another top search engine, does not offer access to search statistics.
Google Trends allows the user to see how interest in a search query changes over time. It can also highlight differences between cities, countries and between regions in large countries. Google Trends can show the relative popularity of various entities such as a specific film, literary subject or similar. This study analyzed and assessed the availability of signals and type of insights that can be extracted from topics and specific terms related to child marriage. It follows similar studies from Google on influenza and dengue fever epidemics, and our own previous project on migration flows.
- Topic: A topic in Google Trends encompasses different search criteria related to the same concept. For the topic "child marriage" that includes searches such as "child marriage", "child brides", and "early marriage".
- Search Term: When finding the trend of a particular search term, the user gets the individual results for exact text strings like "child marriage", "child brides", and "early marriage".
Importantly, all numbers are relative, not absolute numbers, as this is commercially sensitive. This is described by Google as follows:
“Google Trends adjusts search data to make comparisons between terms easier. Otherwise, places with the most search volume would always be ranked highest. To do this, each data point is divided by the total searches of the geography and time range it represents, to compare relative popularity. The resulting numbers are then scaled to a range of 0 to 100.” (source)
“The numbers that appear show total searches for a term relative to the total number of searches done on Google over time. A line trending downward means that a search term's relative popularity is decreasing. But that doesn't necessarily mean the total number of searches for that term is decreasing. It just means its popularity is decreasing compared to other searches.” (source)
Consequently, we will not know if more or fewer searches are made about child marriage, but we can expect to see if it is a topic that is comparatively more or less in focus in people's searches through the years.
The global trend between January 2008 and April 2016 for the topic 'Child marriage' is shown below.
Although Google at times show main news stories at peaks, that is not the case here. We see that the trend is mainly going up, showing an increased comparative interest in child marriage. There are main peaks in the months of September 2013, June 2015, and March 2016.
As Google Trends also makes it possible to look at news searches, YouTube searches, image searches and more individually, it is possible to see whether searches for news about child marriage also peaked in September 2013, June 2015, and March 2016 making it all the more likely that it was (mainstream) news stories that drove the greater interest and number of searches.
Regular Google searches and Google News searches for the topic "Child marriage" share some peaks (notably September 2013 and June 2015), but there are also quite a few differences.
The increased focus on child marriage in September 2013 seems to be driven to some degree by a story about the death of an 8-year old girl bride from Yemen. There was also focus on Nigerian child brides in the news during that same month. In June 2015, mainstream media wrote about child brides in Africa around the Day of the African Child.
Although inconclusive, an assumption can be made that news stories are a factor in driving people's search behaviour, and therefore potentially people's focus of interest for a given period of time. YouTube search trends (not depicted here) also have June 2015 and September 2013 as main peaks.
Case Study: India
Apart from seeing trends in the global search behaviour, this study looked at India as an individual case study. For the topic of “child marriage” a certain seasonal pattern can be observed in the trend line after the year 2011. Discussions on the topic peak during the months of October and November of each year.
Both overall trends and peaks are very different from the global searches, showing great regional differences. Breaking it further down also shows big differences between Indian states.
A last test we do with the Google Trends data is to see if local differences in searches correlate with differences in the prevalence of child marriage. We compare the Google Trends data to a census completed for India in 2011 that looks at the age of girls and women married within that year. We also compare both to the National Family Health Survey from 2015-16 (NFHS-4). In NFHS-4, the indicator is the percentage of women aged 20-24 years who were married before the age of 18 - in circa 2011.
In the table below, we show how the states rank within a number of metrics (numbers are ranks, not absolute numbers or percentages). From the left we have Google Trends, then the 2011 Census (Urban, Rural, Total), then NFHS-4 (Urban, Rural, Total), and lastly we have also included Literacy Rate from the Census, as a separate, often mentioned explanatory factor in child marriage rates.
The darker the red, the higher the relative number of searches on Google, the higher the child marriage rate, and the lower the literacy rate.
| State | Google Trends | Census, Urban | Census, Rural | Census, Total | NFHS, Urban | NFHS, Rural | NFHS, Total | Literacy Rate |
|---|---|---|---|---|---|---|---|---|
| 15 | 10 | 11 | 7 | |||||
| 14 | 10 | 7 | 8 | 3 | 4 | 3 | 2 | |
| 4 | 3 | 4 | 4 | 5 | 7 | 4 | 21 | |
| 3 | 1 | 3 | 3 | 2 | 2 | 2 | 29 | |
| 12 | 18 | 18 | 22 | |||||
| 13 | 7 | 5 | 6 | |||||
| 9 | 17 | 17 | 17 | 4 | ||||
| 18 | 4 | 6 | 7 | 14 | ||||
| 10 | 16 | 20 | 19 | 6 | 13 | 10 | 17 | |
| 18 | 16 | 16 | 8 | |||||
| 20 | 19 | 19 | 25 | |||||
| 2 | 5 | 2 | 2 | 26 | ||||
| 16 | 2 | 9 | 9 | 8 | 9 | 9 | 18 | |
| 11 | 12 | 13 | 13 | 1 | ||||
| 8 | 7 | 11 | 11 | 9 | 3 | 6 | 23 | |
| 16 | 8 | 14 | 14 | 7 | 8 | 8 | 9 | |
| 16 | 15 | 16 | 12 | |||||
| 18 | 11 | 12 | 19 | |||||
| 5 | 6 | 12 | 12 | 20 | ||||
| 17 | 17 | 17 | 5 | |||||
| 7 | 18 | 18 | 18 | 16 | ||||
| 1 | 13 | 4 | 5 | 27 | ||||
| 10 | 16 | 14 | 10 | |||||
| 14 | 15 | 14 | 15 | 13 | 12 | 13 | 11 | |
| 11 | 5 | 7 | 28 | |||||
| 4 | 6 | 5 | 3 | |||||
| 13 | 11 | 10 | 10 | 24 | ||||
| 5 | 14 | 14 | 15 | 13 | ||||
| 12 | 8 | 1 | 1 | 1 | 1 | 1 | 15 |
From the table above, it is evident to the naked eye that there are some dark rows; states that score poorly across the board. The northern and eastern states of West Bengal, Bihar, Assam, Jharkhand, and Rajastan seem to have some way to go before they are child marriage free, while states like Kerala, Haryana and Tamil Nadu are doing better. Chhattisgarh has the lowest rate of child marriage according to NFHS.
The table above displays some rows in which the colors of individual cells are similar, indicating that the ranking in different variables is also similar. Below we use the Kendall rank correlation coefficient (Kendall's Tau) to measure how much the variables are correlated.
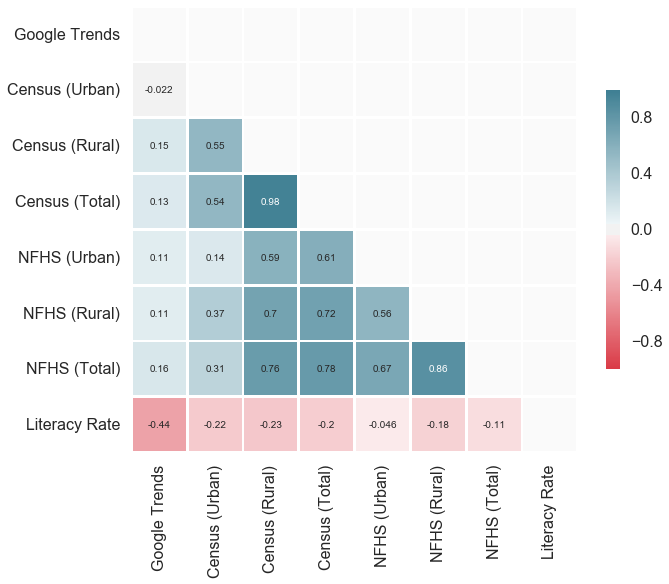
While the Census (Total) and NFHS (Total) correlate strongly (Kendall's Tau: 0.78/Spearman's Rho: 0.92), meaning that states ranking high in one tend to rank high in the other as well, the rank correlations between them and the Google Trends data are much lower.
Based on the very modest correlation between Google Trends data and child marriage prevalence data we do not believe that Google Trends can shed much light on the child marriage trends. Estimating actual child marriage rates is definitely a stretch, but seeing trends at a monthly scale as well as global and sub-national changes much more rapidly than official censuses and major surveys could be a possibility if more research is carried out.
As we have used the Google Trends topic of "Child marriage", we are at a data-driven, predefined combination of seach terms. Nonetheless, further analysis should look at other time periods and combinations of individual search terms.
For this analysis, data from Ethiopia was insufficient at sub-national level, and only Addis Ababa is included in the subregional level. The search trend since January 2008 can be seen below. January 2009 was the month where child marriage related searches were most popular.